¿Es realmente necesario normalizar o estandarizar datos de series de tiempo antes de analizarlos?

En mi último proyecto fui consultado con esta duda varias veces, acá publico mi opinión al respecto y cómo se ejecuta en Python.
Basado en mi ámbito de trabajo cuando las series de tiempo posee features (variables independientes) y target (variable dependiente) con órdenes de magnitudes muy diferentes suelo escalar los datos.
¿Cuál es la diferencia entre normalizar y estandarizar?
Normalizar es escalar los datos desde su valores originales a un rango entre 0 y 1, por lo tanto se requiere conocer cual es el valor mínimo y máximo del universo para realizar la operación. Una lista de la manera de hacerlo esta en wikipedia.
Normalmente, trabajo con serie temporales proveniente de registros de procesos industriales y son no estacionarias desde el punto de vista estadístico, asi que normalizar no suele ser beneficioso. Sin embargo, existen algoritmos de machine learning que requieren que la data sea normalizada.
Por otra parte, estandarizar se refiere a escalar la distribución de los datos de forma tal que la media de los valores observados sea igual a 0 y su desviación estándar igual a 1. (wikipedia)
En general, los algoritmos de machine learning que se basen sobre la hipótesis que los datos poseen una distribución gaussiana requieren que los mismos sean estandarizados. Sin embargo, la selección de la manera de escalar la data no es una tarea de una sola vía, depende mucho de las circunstancias y de los resultados del análisis descriptivo inicial del problema.
¿Cómo se puede hacer?
Las maneras de lograr este tipo de transformación son variadas pero Python brinda un ecosistema muy versátil que simplifica el trabajo. La librería de Scikit-learn cuenta con un modelo llamado Preprocessing con funciones útiles y de fácil implementación.
En este ejemplo le muestro como usar la función MinMaxScaler, cuya transformación se basa en:
Función matemática de minimización
\[\begin{aligned} X_{std} &= \frac{X - {min}(X)}{\text{max}(X) - \text{min}(X)} \\ X_\text{scaled} &= X_{std} \left(\text{max} - \text{min}\right) - \text{min} \end{aligned}\]-
Carga de los módulos
1 2 3 4 5
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from sklearn.preprocessing import MinMaxScaler, StandardScaler
-
Preparación de los datos de ejemplo.
Usaremos datos obtenidos a partir de la simulación de un proceso de transporte de una mezcla de hidrocarburos a través de una tubería.
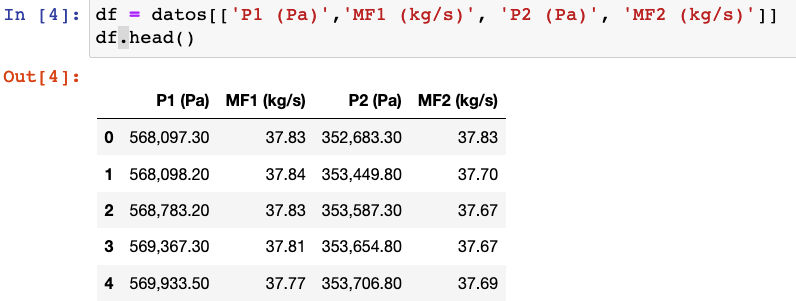
Como se puede observar el orden de magnitud es my distinto entre las variables Pi, las cuales corresponden a presiones del fluido, con respecto a las variables MF, que reportan el flujo másico. Un gráfico comparativo de estas variables, empleando la función ‘’violinplot” de Seaborn, seria:
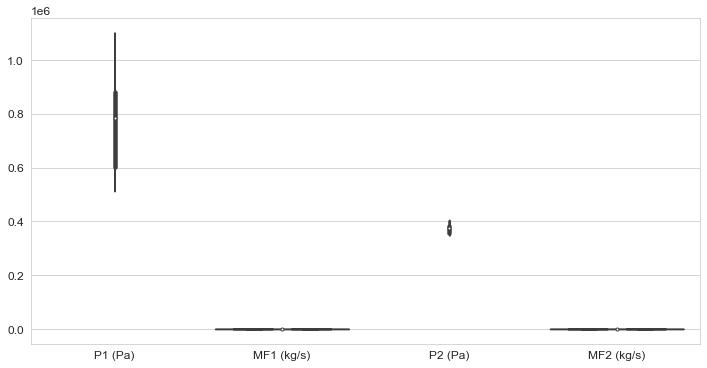
Claramente, es muy poco útil.
-
Creación de escalador
El siguiente paso es entrenar el escalador con los datos de interes y proceder al escalaiento empleando la funcion transform que dispone MinMaxScaler.
1 2 3 4 5 6 7 8 9 10 11 12
# Conversion de los datos a numpy array valores = df.values # Construcion de escalador scaler = MinMaxScaler(feature_range=(0, 1)) scaler = scaler.fit(valores) # Escalamiento de los valores normalizados = scaler.transform(valores) df_normalizados = pd.DataFrame(normalizados, index=df.index, columns=df.columns)
Los resultados los podemos ver el nuevo violinplot
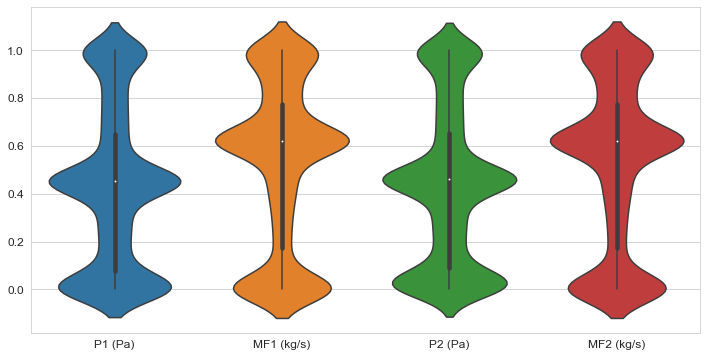
Ahora es posible comparar los datos, su distribución y hacer un análisis preliminar del proceso.
-
Regresión sobre los datos normalizados a la escala original
Es muy sencillo, ya que se dispone de la función inverse_transform, la cual se implementa de la siguiente manera:
1 2 3
unidades_ing = scaler.inverse_transform(normalizados) for i in range(10): print(unidades_ing[i,:])
El detalle de este código y un ejemplo adicional de la estandarización se encuentra en el siguiente enlace.